





NVFP4: Định dạng 4-Bit đầu tiên của NVIDIA mang độ chính xác 16-Bit vào kỷ nguyên Blackwell
Nếu như trước đây, việc giảm độ chính xác xuống 4-bit thường đồng nghĩa với việc đánh đổi chất lượng mô hình, thì sự xuất hiện của định dạng số NVFP4 trên nền tảng kiến trúc Blackwell đã thay đổi hoàn toàn cục diện. Không chỉ giúp giảm tới 3.5 lần dung lượng bộ nhớ so với chuẩn FP16, NVFP4 còn là công nghệ tiên phong cho phép các AI Factory huấn luyện những siêu mô hình hàng nghìn tỷ tham số ngay trên nền tảng 4-bit. Nhờ cơ chế chia nhỏ khối dữ liệu và hệ số tỷ lệ 2 lớp thông minh, công nghệ này mang lại hiệu suất tốc độ vượt trội mà vẫn duy trì được độ ổn định ngang hàng với các định dạng 16-bit truyền thống.

Kiến trúc Two Level Scaling - Bí mật đằng sau độ chính xác tuyệt đối
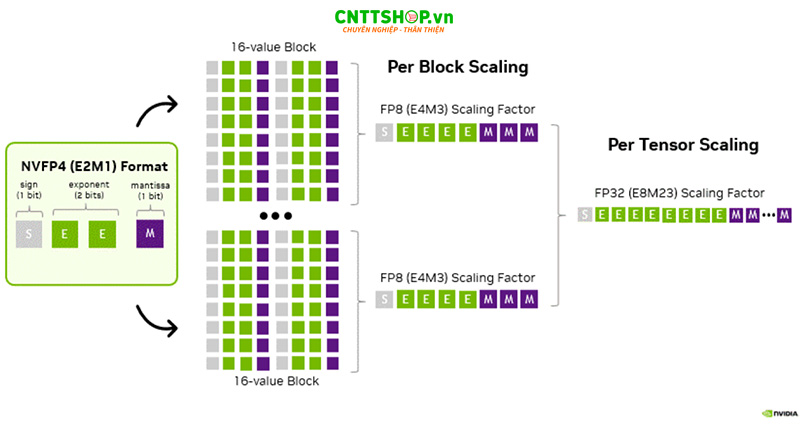
NVFP4 giải quyết bài toán hóc búa nhất của kỹ thuật lượng tử hóa là duy trì độ chính xác số học trên một dải động rộng. Thay vì áp dụng phương pháp nén truyền thống thường gây mất mát dữ liệu, NVIDIA đã triển khai chiến lược chia tỷ lệ hai cấp độ độc quyền trên nền tảng phần cứng Blackwell.
Điểm khác biệt lớn nhất nằm ở cách tổ chức dữ liệu khi NVFP4 thu hẹp phạm vi xử lý xuống các khối vi mô chỉ chứa 16 phần tử (micro-block), thay vì gom nhóm 32 giá trị như chuẩn MXFP4 tiền nhiệm. Việc giảm một nửa kích thước khối này cho phép hệ thống thích ứng cục bộ tốt hơn với dải động của dữ liệu. Nhờ đó, các giá trị ngoại lai hoặc những biến động nhỏ trong trọng số mô hình được bảo toàn trọn vẹn thay vì bị làm tròn thiếu chính xác. Để tối ưu hóa, mỗi khối vi mô này được quản lý bởi một hệ số tỷ lệ E4M3 chi tiết kết hợp cùng một hệ số tỷ lệ FP32 thứ cấp áp dụng cho toàn bộ tensor. Sự phối hợp nhịp nhàng giữa hai lớp xử lý giúp giảm thiểu tối đa sai số lượng tử hóa và đảm bảo tín hiệu đầu ra giữ được độ trung thực cao nhất so với dữ liệu gốc.
Huấn luyện mô hình lớn trên nền tảng 4-bit
Trước khi NVFP4 xuất hiện, các định dạng 4-bit chỉ được xem là giải pháp dành riêng cho giai đoạn suy luận vì chúng thiếu độ ổn định cần thiết để duy trì quá trình hội tụ trong huấn luyện. NVIDIA đã phá vỡ định kiến này bằng việc xây dựng một quy trình huấn luyện chuyên biệt trên nền tảng Blackwell. Hệ thống áp dụng kỹ thuật làm tròn ngẫu nhiên (Stochastic Rounding) để đảm bảo dòng chảy của gradient không bị tắc nghẽn hay sai lệch, giúp triệt tiêu hiện tượng thiên vị làm tròn vốn thường gây ra sự phân kỳ trong các mô hình lớn.
Kết quả thực nghiệm đã chứng minh sức mạnh của phương pháp này trên một mô hình 12 tỷ tham số được huấn luyện với 10 nghìn tỷ token. Biểu đồ tổn thất (Loss Curve) của NVFP4 bám sát gần như tuyệt đối so với chuẩn FP8, cho thấy không có bất kỳ sự suy giảm nào về khả năng học hỏi hay độ chính xác của mô hình. Các nhà phát triển giờ đây có thể tận dụng tốc độ tính toán ma trận nhanh hơn gấp 7 lần trên các hệ thống GB200 để rút ngắn thời gian phát triển các mô hình AI thế hệ mới.
Hiện thực hóa sức mạnh NVFP4 với NVIDIA DGX Spark
Những đột phá về thuật toán nén 4 bit sẽ khó phát huy tối đa tác dụng nếu thiếu đi nền tảng phần cứng tương xứng. Đây chính là lúc kiến trúc Blackwell trên hệ thống siêu máy tính nhỏ gọn NVIDIA DGX Spark khẳng định vai trò của mình. Cỗ máy này được thiết kế chuyên biệt để chuyển hóa những ưu điểm kỹ thuật của NVFP4 thành hiệu năng thực tế ngay tại văn phòng làm việc của các nhà phát triển.

Nhờ khả năng hỗ trợ nguyên bản định dạng NVFP4, DGX Spark gói gọn sức mạnh tính toán lên tới 1 Petaflop cùng 128GB bộ nhớ thống nhất vào một thiết kế để bàn nhỏ gọn. Sự kết hợp hoàn hảo giữa phần mềm tối ưu và phần cứng chuyên dụng cho phép hệ thống xử lý mượt mà các tác vụ AI hạng nặng vốn trước đây là rào cản lớn với các máy trạm thông thường. Các thử nghiệm thực tế cho thấy DGX Spark có thể tinh chỉnh mô hình Llama 3.3 70B bằng phương pháp QLoRA hay tạo sinh hình ảnh chất lượng cao với tốc độ chỉ 2.6 giây mỗi khung hình.
Tối ưu dung lượng lưu trữ cùng hiệu suất năng lượng vượt trội
NVFP4 không chỉ giải quyết bài toán về độ chính xác mà còn mang lại cuộc cách mạng về tài nguyên phần cứng. Về mặt lưu trữ, mỗi giá trị NVFP4 thực tế chỉ chiếm khoảng 4.5 bit nếu tính cả phần chi phí quản lý của các hệ số tỷ lệ. Con số khiêm tốn này giúp giảm dung lượng bộ nhớ mô hình xuống khoảng 3.5 lần so với chuẩn FP16 và khoảng 1.8 lần so với chuẩn FP8. Sự giải phóng tài nguyên này đặc biệt có ý nghĩa với các hệ thống quy mô lớn như GB300 NVL72, tạo điều kiện lý tưởng cho việc triển khai các mô hình ngôn ngữ khổng lồ mà không gặp áp lực về giới hạn phần cứng.
Bên cạnh đó, việc giảm độ chính xác còn kéo theo lợi ích to lớn về chi phí vận hành. Các phép toán 4-bit tiêu tốn ít điện năng hơn đáng kể cho quá trình di chuyển dữ liệu và tính toán số học. Khi kết hợp với các cải tiến tản nhiệt trên kiến trúc Blackwell, hiệu suất trên mỗi watt điện được cải thiện ngoạn mục. Các số liệu thực nghiệm cho thấy hệ thống Blackwell Ultra có thể đạt hiệu quả năng lượng cao gấp 50 lần so với thế hệ Hopper tiền nhiệm khi vận hành các mô hình GPT-MoE kích thước 1.8 nghìn tỷ tham số.
Kết luận
Sự ra đời của định dạng NVFP4 không chỉ đơn thuần là một bước tiến về kỹ thuật nén dữ liệu mà còn tái định nghĩa hoàn toàn cách thức xây dựng và vận hành các nhà máy AI hiện đại. Bằng việc xóa bỏ ranh giới giữa tốc độ xử lý và độ chính xác tính toán, NVIDIA đã trao cho các nhà phát triển quyền năng để huấn luyện những mô hình ngôn ngữ khổng lồ nhanh hơn và tiết kiệm năng lượng hơn bao giờ hết.
Với sự hỗ trợ mạnh mẽ từ hệ sinh thái phần mềm như TensorRT Model Optimizer hay vLLM cùng nền tảng phần cứng Blackwell đột phá, rào cản để tiếp cận công nghệ 4-bit đã hoàn toàn được gỡ bỏ. Đây chính là thời điểm thuận lợi để các doanh nghiệp nắm bắt cơ hội, tối ưu hóa hạ tầng tính toán và sẵn sàng cho những bước nhảy vọt tiếp theo trong kỷ nguyên AI tạo sinh. Liên hệ ngay CNTTShop để được tư vấn giải pháp phần cứng AI chuyên dụng.





 là gì?")





Bình luận bài viết!