











NVIDIA Blackwell là gì? GPU mạnh mẽ với công nghệ đột phá cho AI và HPC
Sự bùng nổ của trí tuệ nhân tạo (AI) và tính toán hiệu năng cao (HPC) đã thúc đẩy các công ty công nghệ hàng đầu trên thế giới đầu tư mạnh mẽ vào nghiên cứu và phát triển các công nghệ tiên tiến nhằm đáp ứng nhu cầu ngày càng tăng cho lĩnh vực này. AI và HPC đã trở thành các yếu tố then chốt trong việc giải quyết các vấn đề phức tạp, từ việc dự đoán thời tiết, phân tích dữ liệu lớn, đến phát triển các mô hình học sâu phục vụ cho nhận dạng giọng nói, hình ảnh và video.
Các tập đoàn như NVIDIA, Google, Microsoft và IBM..vv đã liên tục tung ra thị trường hàng loạt các sản phẩm và giải pháp mới, bao gồm các GPU hiệu năng cao, hệ thống máy tính lượng tử, và các nền tảng phần mềm tối ưu hóa cho AI và HPC. Trong đó, NVIDIA Blackwell là một GPU mạnh mẽ hàng đầu hiện nay, với những cải tiến đột phá về hiệu suất tính toán và khả năng xử lý dữ liệu, nó đang tăng tốc thúc đẩy cách mạng hóa lĩnh vực AI và tính toán hiệu năng cao.
NVIDIA Blackwell là gì?
NVIDIA Blackwell là GPU mạnh mẽ cho AI và tăng tốc tính toán, có kiến trúc mới chứa số lượng bóng bán dẫn khổng lồ tới 208 tỷ transistor. GPU Blackwell đạt được hiệu suất tính toán cao nhất chưa từng có trên một chip đơn lẻ, lên tới 20 petaFLOPS (20 triệu tỷ phép tính mỗi giây) mang tới khả năng xử lý các tác vụ tính toán phức tạp và mô hình AI lớn một cách hiệu quả và nhanh chóng.

Trước khi Blackwell ra đời, NVIDIA đã có một lịch sử dài phát triển các GPU hiệu năng cao, bắt đầu từ dòng GeForce cho chơi game, đến dòng Tesla và DGX cho tính toán hiệu năng cao và AI. GPU Blackwell tiếp nối thành công của kiến trúc Hopper, nhằm mục tiêu cung cấp hiệu suất cao hơn và khả năng xử lý mạnh mẽ hơn cho các ứng dụng AI và HPC.
Kiến trúc mới đột phá của GPU NVIDIA Blackwell.
GPU NVIDIA Blackwell được thiết kế bao gồm hai khuôn (Die) Silicon có kích thước Reticle, đây là khuôn mẫu dùng trong quá trình quang khắc để tạo ra các mạch điện trên chip. Hai khuôn (Die) này được kết nối với nhau bằng một liên kết chip-to-chip có băng thông cao lên tới 10 terabyte mỗi giây (TB/s). Liên kết này giúp tạo ra một GPU thống nhất, cung cấp hiệu suất và khả năng xử lý dữ liệu cao hơn.
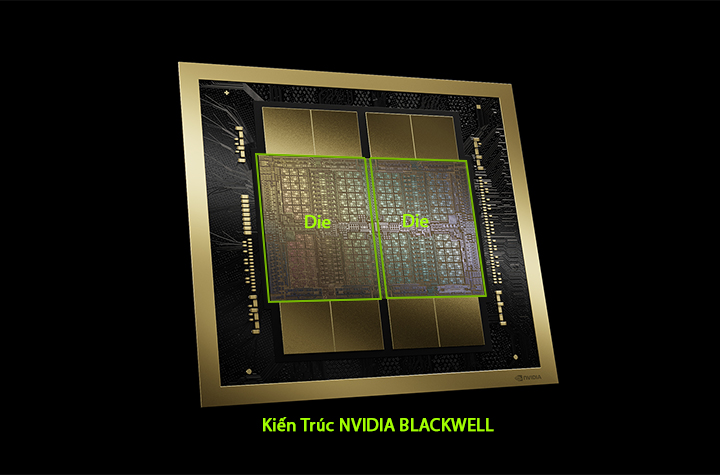
Kiến trúc NVIDIA Blackwell đánh dấu một bước tiến đáng kể trong công nghệ GPU, đặc biệt là cho các ứng dụng AI sinh học và tính toán hiệu năng cao (HPC). Được thiết kế để kế nhiệm các kiến trúc Hopper và Ada Lovelace, Blackwell tập trung vào việc cải thiện tính toán AI với các tính năng tiên tiến như lõi Tensor thế hệ thứ năm và công nghệ Transformer Engine mới cải thiện hiệu quả và thông lượng tính toán.
Tăng tốc suy luận AI, đào tạo AI và tính toán với Transformer Engine.
Trên GPU NVIDIA Blackwell áp dụng Transformer Engine thế hệ thứ hai, đây là một thư viện để tăng tốc các mô hình Transformer trên GPU NVIDIA. Nó cung cấp hiệu suất tốt hơn với việc sử dụng bộ nhớ thấp hơn trong cả đào tạo và suy luận. Thư viện bao gồm sử dụng độ chính xác dấu phẩy động 8 bit (FP8) trên GPU Hopper.
Transformer thế hệ thứ hai của NVIDIA Blackwell sử dụng công nghệ Blackwell Tensor Core kết hợp với các đổi mới từ NVIDIA® TensorRT™-LLM và NeMo™ Framework, giúp tăng tốc quá trình suy luận và đào tạo cho các mô hình ngôn ngữ lớn (LLMs) và các mô hình Mixture-of-Experts (MoE).
Một tính năng nổi bật của Transformer Engine thế hệ thứ hai là khả năng hỗ trợ các độ chính xác tính toán mới, bao gồm các định dạng microscaling được xác định bởi cộng đồng, điều này giúp tăng độ chính xác và dễ dàng thay thế cho các độ chính xác lớn hơn. Công nghệ này cũng sử dụng các kỹ thuật điều chỉnh tỉ mỉ gọi là micro-tensor scaling, tối ưu hóa hiệu suất và độ chính xác, cho phép sử dụng độ chính xác số thực 4-bit (FP4). Nó tăng gấp đôi hiệu suất và kích thước của các mô hình ngôn ngữ lớn thế hệ tiếp theo mà bộ nhớ có thể hỗ trợ, đồng thời vẫn duy trì độ chính xác cao.
Bảo mật dữ liệu và mô hình AI.
GPU NVIDIA Blackwell được xây dựng với công nghệ "NVIDIA Confidential Computing". Công nghệ này bảo vệ dữ liệu nhạy cảm và các mô hình AI khỏi sự truy cập trái phép bằng các biện pháp bảo mật dựa trên phần cứng. Blackwell là GPU đầu tiên trong ngành có khả năng hỗ trợ TEE-I/O, đồng thời cung cấp giải pháp tính toán bảo mật hiệu quả nhất với các host có khả năng TEE-I/O và bảo vệ trực tiếp qua NVIDIA NVLink.
Công nghệ này cho phép thực hiện tính toán bảo mật mà vẫn đạt hiệu suất gần như tương đương với chế độ không mã hóa. Điều này cho phép các doanh nghiệp bảo mật các mô hình lớn một cách hiệu quả, bảo vệ sở hữu trí tuệ AI và cho phép đào tạo AI, suy luận và học tập liên kết một cách an toàn.
Kết nối tốc độ cao với NVLink và NVLink Switch.
Để có tới 208 tỷ bóng bán dẫn transistor trên một GPU Blackwell, NVIDIA đã liên kết hai khung (die) chip 104 tỷ bóng bán dẫn với nhau với băng thông 10 TB/s tạo thành một GPU Blackwell mạnh mẽ duy nhất. Nhưng đây chỉ là một GPU đơn lẻ, để khai thác toàn bộ tiềm năng của điện toán exascale và các mô hình AI nghìn tỷ thông số cần kết nối liên lạc nhanh chóng, liền mạch giữa nhiều GPU trong cụm máy chủ.
Kết nối NVIDIA NVLink thế hệ thứ năm có thể mở rộng tới 576 GPU Blackwell để giải phóng hiệu năng được tăng tốc cho các mô hình AI có tham số nghìn tỷ và đa nghìn tỷ ví dụ như Superchip GB200 Grace Blackwell.
Chip chuyển mạch NVIDIA NVLink cho phép băng thông GPU 130TB/giây trong một miền NVLink 72-GPU (NVIDIA GB200 NVL72) và mang lại hiệu quả băng thông gấp 4 lần với hỗ trợ Giao thức giảm thiểu và tổng hợp phân cấp có thể mở rộng NVIDIA (SHARP)™ FP8. Chip chuyển mạch NVIDIA NVLink hỗ trợ các cụm ngoài một máy chủ ở cùng tốc độ kết nối ấn tượng 1,8TB/s. Các cụm nhiều máy chủ có giao tiếp GPU quy mô NVLink cân bằng với khả năng tính toán tăng lên, do đó NVL72 có thể hỗ trợ thông lượng GPU gấp 9 lần so với một hệ thống 8 GPU.
Tăng tốc độ truy vấn cơ sở dữ liệu với công nghệ giải nén trên GPU NVIDIA Blackwell.
Như chúng ta đã biết trong một hệ thống máy tính tính toán thì việc xử lý dữ liệu thường được dựa vào CPU, nhưng với GPU NVIDIA Blackwell được tích hợp công nghệ giải nén (Decompression Engine) một tính năng mới nhằm cải thiện hiệu suất phân tích dữ liệu và quá trình xử lý cơ sở dữ liệu.
Với khẳ năng giải nén này và khả năng truy cập vào lượng lớn bộ nhớ qua CPU NVIDIA Grace™ với đường truyền tốc độ cao 900GB/s băng thông hai chiều sẽ giúp tăng tốc toàn bộ quy trình truy vấn cơ sở dữ liệu. Điều này nâng cao hiệu suất tối đa trong phân tích dữ liệu và khoa học dữ liệu, đồng thời hỗ trợ các định dạng nén mới như LZ4, Snappy và Deflate.
Cơ chế này không chỉ giúp tăng tốc độ tạo ra giá trị từ dữ liệu mà còn giảm chi phí liên quan, đem lại lợi ích đáng kể cho các ứng dụng yêu cầu xử lý và phân tích lượng lớn dữ liệu, chẳng hạn như Apache Spark, một công cụ quan trọng trong việc xử lý và phân tích dữ liệu.
Công cụ RAS cung cấp độ tin cậy, tính sẵn sàng và khả năng bảo trì.
Công cụ RAS (eliability, Availability, Serviceability) trên GPU NVIDIA Blackwell được thiết kế để nâng cao khả năng hoạt động ổn định và hiệu quả của hệ thống. Công cụ RAS này có chức năng phát hiện sớm các lỗi tiềm ẩn có thể xảy ra, giúp giảm thiểu thời gian ngừng hoạt động của hệ thống.
NVIDIA sử dụng khả năng quản lý dự đoán dựa trên AI để liên tục theo dõi hàng nghìn điểm dữ liệu trên phần cứng và phần mềm, nhằm đánh giá tình trạng hoạt động tổng thể. Điều này cho phép dự đoán và ngăn chặn các nguyên nhân gây ra thời gian chết và kém hiệu quả, từ đó xây dựng khả năng phục hồi thông minh, tiết kiệm thời gian, năng lượng và chi phí tính toán.
Ngoài ra, RAS trên NVIDIA Blackwell cung cấp thông tin chẩn đoán sâu rộng, giúp xác định các khu vực có vấn đề và lập kế hoạch bảo trì. Động cơ này giúp giảm thời gian giải quyết sự cố bằng cách nhanh chóng xác định nguồn gốc của vấn đề và giảm thiểu thời gian ngừng hoạt động bằng cách tạo điều kiện cho việc khắc phục hiệu quả.
Các sản phẩm GPU Blackwell cho AI và HPC của NVIDIA
Các sản phẩm GPU Blackwell của NVIDIA bao gồm các mô hình như B100, B200, và GB200, mỗi loại có các đặc điểm và công suất khác nhau phù hợp cho các nhu cầu cụ thể:
- B100 Blackwell GPU: Đây là một GPU cung cấp hiệu suất cao với khả năng xử lý các tác vụ AI và tính toán khoa học dữ liệu. Nó được thiết kế để đạt hiệu suất tối ưu trong các hoạt động tensor dày và thưa với khả năng xử lý mạnh mẽ cho dữ liệu FP4 và INT8. B100 có bộ nhớ lớn, hỗ trợ lên đến 192GB, cùng băng thông bộ nhớ và NVLink tốc độ cao. GPU B100 có mức tiêu thụ năng lượng ở mức 700W, được thiết kế để cân bằng giữa hiệu suất và tiêu thụ năng lượng.
- B200 Blackwell GPU: Mẫu này mạnh mẽ hơn B100, cung cấp hiệu suất cao hơn trong cả các tác vụ dày và thưa cho tensor FP4 và FP6/FP8, với khả năng xử lý dữ liệu INT8 cực kỳ nhanh. B200 cũng có bộ nhớ lên đến 192GB và hỗ trợ băng thông lớn, phù hợp với các ứng dụng đòi hỏi hiệu suất xử lý dữ liệu cao. GPU B200 có mức tiêu thụ điện năng lên đến 1000W. Đây là một phiên bản mạnh mẽ hơn, được tối ưu hóa cho các tác vụ đòi hỏi hiệu suất cao.
- GB200 Grace Blackwell Superchip: Là sự kết hợp của hai GPU B200 với CPU Grace của NVIDIA thông qua một liên kết NVLink tốc độ cao, GB200 được thiết kế cho các ứng dụng đòi hỏi hiệu suất cực cao và băng thông bộ nhớ lớn. Superchip này hỗ trợ bộ nhớ HBM3e lên đến 384 GB với băng thông lên đến 16 TB/s, tối ưu cho các tác vụ khoa học dữ liệu và AI phức tạp. Các bộ xử lý kép B200 và một CPU Grace trong cấu hình này có thể tiêu thụ tổng cộng lên đến 2700W.
Các hệ thống sử dụng GPU NVIDIA Blackwell
Các hệ thống tích hợp GPU Blackwell của NVIDIA cần khả năng linh hoạt và mạnh mẽ trong việc đáp ứng nhu cầu của các tác vụ khác nhau từ doanh nghiệp cho đến nghiên cứu khoa học, đồng thời khẳng định vị thế của NVIDIA trong lĩnh vực công nghệ GPU hiện đại.
- Trung tâm dữ liệu và máy chủ: Các GPU Blackwell được tích hợp vào các trung tâm dữ liệu để xử lý các tác vụ tính toán hiệu năng cao và AI. Ví dụ, các máy chủ được trang bị GPU Blackwell có thể được sử dụng để xử lý các mô hình AI lớn, phân tích dữ liệu khoa học, và xử lý đồ họa nặng.
- Các hệ thống DGX SuperPOD của NVIDIA: Đây là các hệ thống được thiết kế sẵn, chứa nhiều GPU Blackwell, được tối ưu hóa cho việc triển khai AI và HPC. SuperPODs cung cấp khả năng mở rộng và hiệu quả cao, là giải pháp lý tưởng cho các tác vụ như đào tạo mô hình AI quy mô lớn và phân tích dữ liệu phức tạp.
- Nền tảng điện toán đám mây: Các nhà cung cấp dịch vụ đám mây như AWS, Google Cloud, và Microsoft Azure sử dụng GPU Blackwell để cung cấp khả năng xử lý AI mạnh mẽ cho khách hàng của họ thông qua các dịch vụ đám mây. Các GPU này cho phép các doanh nghiệp thực hiện các tác vụ như suy luận AI, đào tạo mô hình, và phân tích dữ liệu mà không cần đầu tư trực tiếp vào phần cứng.
- Giải pháp AI tại chỗ: Các doanh nghiệp có thể tích hợp GPU Blackwell trực tiếp vào hệ thống IT của họ để xử lý các tác vụ AI và dữ liệu ngay tại chỗ. Điều này giúp giảm độ trễ, tăng bảo mật dữ liệu và tối ưu hóa hiệu suất xử lý.
CNTTShop - Đơn vị uy tín cung cấp các sản phẩm và dịch vụ của NVIDIA, AI và HPC
GPU NVIDIA Blackwell đại diện cho một bước tiến mới trong công nghệ GPU, thiết lập chuẩn mới cho hiệu suất và hiệu quả năng lượng trong lĩnh vực AI và tính toán hiệu năng cao (HPC). Với các đổi mới như Động cơ Transformer thế hệ thứ hai, lõi Tensor thế hệ thứ năm, và khả năng tính toán bằng cách sử dụng các định dạng dữ liệu mới như FP4 và FP6, Blackwell mở ra khả năng tăng tốc đáng kể cho các tác vụ AI phức tạp và các ứng dụng HPC đòi hỏi khả năng xử lý dữ liệu lớn và tốc độ cao.
Các GPU Blackwell, đặc biệt là các mô hình B100 và B200, cung cấp khả năng tính toán mạnh mẽ với hỗ trợ cho các hoạt động tensor dày và thưa qua các mức độ chính xác khác nhau (FP4, FP6, FP8, INT8), làm cho chúng phù hợp cho tính toán khoa học và phân tích dữ liệu chi tiết. Ví dụ, mô hình B100 có thể đạt tới 14 PFLOPS trong các hoạt động tensor FP4 thưa, trong khi B200 có thể đạt tới 18 PFLOPS.
Để biết thêm thông tin chi tiết kỹ thuật và thông số kỹ thuật về GPU NVIDIA Blackwell, cũng như các giải pháp của NVIDA, AI, HPC vui lòng liên hệ tới chúng tôi để được các chuyên gia tư vấn chính xác.
CNTTShop là đơn vị uy tín, tiên phong trong việc cung cấp các sản phẩm và dịch vụ của NVIDIA, đặc biệt là trong lĩnh vực AI và tính toán hiệu năng cao (HPC). Với việc cung cấp các GPU NVIDIA Blackwell, CNTTShop không chỉ đáp ứng nhu cầu về phần cứng mạnh mẽ mà còn hỗ trợ khách hàng trong việc triển khai các giải pháp AI tiên tiến và các ứng dụng HPC phức tạp. Sự kết hợp giữa các sản phẩm hàng đầu và dịch vụ chuyên nghiệp đã giúp CNTTShop trở thành địa chỉ tin cậy cho các doanh nghiệp và tổ chức khoa học công nghệ trong việc tìm kiếm các giải pháp công nghệ cao.











Bình luận bài viết!
Elon Musk đang thử nghiệm Neuralink rồi bạn, tương lai có thể gắn chip vào để điều khiển hoặc tiếp nhạn thông tin