











Kiến trúc của Nvidia Blackwell GPU NVIDIA B100, B200 và GB200
Tại triển lãm GTC 2024 vừa qua NVIDIA đã giới thiệu một loạt các GPU công nghệ mới Blackwell B100, B200 và GB200, thế hệ GPU mới ưu việt nhất chuyên dụng cho các mô hình AI tạo sinh, máy học, xử lý Bigdata và các Datacenter lớn đặc biệt các mô hình tính toán, suy luận với nhiều nghìn tỷ tham số (multi-trillion parameter models) trong thời gian thực, những yêu cầu đó sẽ không thể thực hiện được nếu không có những nâng cấp đột phá trong trong kiến trúc của Blackwell GPU. Kiến trúc Blackwell GPU được thiết lập để định nghĩa lại các mô hình AI Tạo Sinh và xây xựng các HPC (High-performance computing) với khả năng tính toán song song chưa từng có.

Kiến trúc GPU Blackwell được đặt tên để vinh danh nhà toán học nổi tiếng người Mỹ, Tiến sĩ David Harold Blackwell, một người có rất nhiều đóng góp cho lý thuyết xác suất, lý thuyết trò chơi và thống kê. Việc đặt tên này để thể hiện tính đột phá và khả năng tính toán vượt trội của dòng sản Blackwell GPU. NVIDIA đã cải thiện mọi khía cạnh trong thiết kế chip để nâng cấp toàn diện thế hệ chip Blackwell GPU, với 06 điểm chính trong việc cải tiến và nâng cấp của kiến trúc Blackwell GPU bao gồm: AI Superchip, Transformer Engine, NVLink thế hệ thứ 5, Công cụ RAS, Secure AI và Decompression Engine
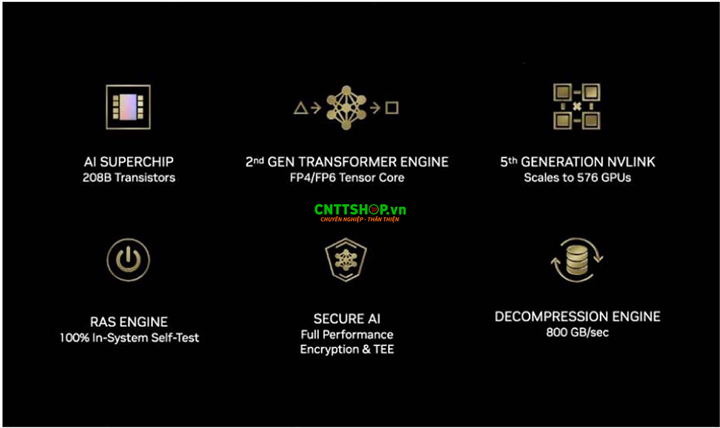
- Một thế hệ Siêu chip mới cho AI Superchip
- Công cụ chuyển đổi thế hệ thứ 2 (Transformer Engine)
- NVLink thế hệ thứ 5
- Công cụ RAS (Reliability, Availability, and Serviceability)
- AI An Toàn (Secure AI)
- Công cụ giải nén (Decompression Engine)
- NVIDIA Blackwell B100 GPU và Blackwell B200 GPU
- NVIDIA Blackwell GB200 GPU
- Kết luận
1. Một thế hệ Siêu chip mới cho AI Superchip
Kiến trúc mới Blackwell GPU chứa 208 tỷ bóng bán dẫn và được sản xuất bằng quy trình TSMC 4NP được xây dựng tùy chỉnh dành riêng cho dòng chip này. Tất cả các dòng sản phẩm của Blackwell đều có hai khuôn giới hạn mặt kẻ ô (reticle-limited dies) được kết nối với nhau thông qua công nghệ siêu kết nối NVLink-C2C 10 terabyte mỗi giây (TB/s) tạo thành một GPU thống nhất. Với công nghệ thiết kế Dual-Chip sẽ tăng gấp đôi tài nguyên tính toán, nâng cao khả năng xử lý dữ liệu và hiệu suất tổng thể.
2. Công cụ chuyển đổi thế hệ thứ 2 (Transformer Engine)
Transformer Engine - công cụ chuyển đổi thế hệ thứ hai sử dụng công nghệ Blackwell Tensor Core tùy chỉnh kết hợp với các cải tiến NVIDIA® TensorRT™-LLM và NeMo™ Framework để tăng tốc độ suy luận và đào tạo cho các mô hình ngôn ngữ lớn (LLM) và mô hình Mixture-of-Experts (MoE). Để tăng cường khả năng suy luận của các mô hình MoE, Blackwell Tensor Cores bổ sung các độ chính xác mới, bao gồm các định dạng vi mô mới do cộng đồng xác định, mang lại độ chính xác cao và dễ dàng thay thế cho các độ chính xác lớn hơn. Blackwell Transformer Engine sử dụng các kỹ thuật chia tỷ lệ chi tiết được gọi là chia tỷ lệ micro-tensor, để tối ưu hóa hiệu suất và độ chính xác cho phép AI dấu phẩy động 4 bit (FP4). Điều này tăng gấp đôi hiệu suất và kích thước của các mẫu máy thế hệ tiếp theo mà bộ nhớ có thể hỗ trợ trong khi vẫn duy trì độ chính xác cao.
3. NVLink thế hệ thứ 5
Công nghệ NVLink giúp mở khóa toàn bộ tiềm năng của GPU bằng cách tăng đáng kể việc lưu chuyển dữ liệu giữa các GPU, giảm thời gian GPU phải chờ đợi dữ liệu, ngoài băng thông rộng hơn, NVLink còn tiết kiệm điện hơn với độ trễ thấp hơn nhiều. Blackwell CPU kết hợp NVIDIA NVLink thế hệ thứ năm có thể liên kết tới 576 GPU vật lý thành một GPU Logic để giải phóng hiệu năng được tăng tốc cho các mô hình AI tạo sinh với nghìn tỷ và đa nghìn tỷ tham số trong thời gian thực.
4. Công cụ RAS (Reliability, Availability, and Serviceability)
Kiến trúc Blackwell GPU bổ sung khả năng phục hồi thông minh với Công cụ Độ tin cậy, Tính khả dụng và Khả năng bảo trì (RAS) chuyên dụng để xác định các lỗi tiềm ẩn có thể xảy ra sớm nhằm giảm thiểu thời gian ngừng hoạt động. Khả năng quản lý dự đoán được hỗ trợ bởi AI của NVIDIA liên tục giám sát hàng nghìn điểm dữ liệu trên phần cứng và phần mềm để biết tình trạng tổng thể nhằm dự đoán và ngăn chặn các nguồn gây ra thời gian ngừng hoạt động và hoạt động kém hiệu quả. Điều này xây dựng khả năng phục hồi thông minh giúp tiết kiệm thời gian, năng lượng và chi phí tính toán.
Công cụ RAS của NVIDIA cung cấp thông tin chẩn đoán chuyên sâu có thể xác định các khu vực cần quan tâm và lập kế hoạch bảo trì. Công cụ RAS giúp giảm thời gian xử lý bằng cách nhanh chóng xác định nguồn gốc của sự cố và giảm thiểu thời gian ngừng hoạt động bằng cách tạo điều kiện khắc phục hiệu quả.
5. AI An Toàn (Secure AI)
Việc bảo vệ dữ liệu khỏi các nguy cơ tấn công cũng như truy nhập trái phép là một yêu cầu tất yếu đổi với tất cả các mô hình AI, mô hình dữ liệu lớn Bgidata hay các mô hình máy học hoặc AI Training. Do vậy việc mã hóa dữ liệu là yêu cầu rất cần thiết cho mọi hệ thống và mô hình. Kiến trúc mới của Blackwell GPU đã nâng cấp công nghệ mã hóa dữ liệu để đảm bảo việc tính toán bảo mật đã có từ kiến trúc NVIDIA Hopper với tốc độ cao hơn rất nhiều. Tính năng bảo mật được nâng cấp kết hợp với cứng mạnh mẽ giúp Blackwell là GPU có khả năng TEE-I/O đầu tiên trong ngành tính toán hiệu năng cao có mã hóa thực hiện trong thời gian thực. Nó cũng đồng thời cung cấp giải pháp điện toán bảo mật hiệu suất cao nhất đối với các Node tính toán cũng như trên toàn bộ NVIDIA NVLink. Blackwell GPU cung cấp tốc độ toàn đối với các dữ liệu được mã hóa gần bằng với các chế độ không được mã hóa. Giờ đây, các doanh nghiệp có thể bảo mật ngay cả những mô hình lớn nhất theo cách hiệu quả, ngoài việc bảo vệ tài sản trí tuệ (IP) AI và cho phép đào tạo, suy luận và học tập liên kết AI một cách an toàn.
6. Công cụ giải nén (Decompression Engine)
Phân tích dữ liệu và quy trình làm việc cơ sở dữ liệu thường dựa vào CPU để tính toán. Khoa học dữ liệu được tăng tốc có thể tăng đáng kể hiệu suất của phân tích từ đầu đến cuối, tăng tốc việc tạo ra giá trị trong khi giảm chi phí. Cơ sở dữ liệu, bao gồm Apache Spark, đóng vai trò quan trọng trong việc xử lý, xử lý và phân tích khối lượng lớn dữ liệu để phân tích dữ liệu.
Công cụ giải nén của Blackwell GPU và khả năng truy cập lượng bộ nhớ khổng lồ trong CPU NVIDIA Grace thông qua liên kết tốc độ cao song công lên đến 900 gigabyte mỗi giây (GB/s)—tăng tốc toàn bộ quy trình truy vấn cơ sở dữ liệu để có hiệu suất dữ liệu cao nhất phân tích và khoa học dữ liệu với sự hỗ trợ cho các định dạng nén mới nhất như LZ4, Snappy và Deflate.
Trong buổi giới thiệu tại triển lãm GTC 2024 của CEO NVidia Jensen Huang đã giới thiệu 03 GPU thuộc thế hệ Blackwell: GB200, B200 và B100, bảng bên dưới là thông số kỹ thuật của các mã GPU Blackwell GB200, B200 và B100
|
|
GB200 |
B200 |
B100 |
|
Type |
Grace Blackwell Superchip |
Discrete Accelerator |
Discrete Accelerator |
|
Memory Clock |
8Gbps HBM3E |
8Gbps HBM3E |
8Gbps HBM3E |
|
Memory Bus Width |
2x2x4096-bit |
2x4096-bit |
2x4096-bit |
|
Memory Bandwidth |
2x8TB/sec |
8TB/sec |
8TB/sec |
|
VRAM |
384GB (2x2x96GB) |
192GB (2x96GB) |
192GB (2x96GB) |
|
FP4 Dense Tensor |
20 PFLOPS |
9 PFLOPS |
7 PFLOPS |
|
INT8/FP8 Dense Tensor |
10 P(FL)OPS |
4.5 P(FL)OPS |
3.5 P(FL)OPS |
|
FP16 Dense Tensor |
5 PFLOPS |
2.2 PFLOPS |
1.8 PFLOPS |
|
TF32 Dense Tensor |
2.5 PFLOPS |
1.1 PFLOPS |
0.9 PFLOPS |
|
FP64 Dense Tensor |
90 TFLOPS |
40 TFLOPS |
30 TFLOPS |
|
Interconnects |
2x NVLink 5 (1800GB/sec) 2x PCIe 6.0 (256GB/sec) |
NVLink 5 (1800GB/sec) PCIe 6.0 (256GB/sec) |
NVLink 5 1800GB/sec) PCIe 6.0 (256GB/sec) |
|
GPU |
2x Blackwell GPU |
Blackwell GPU |
Blackwell GPU |
|
GPU Transistor Count |
416B (2x2x104B) |
208B (2x104B) |
208B (2x104B) |
|
TDP (Thermal Design Power) |
2700W |
1000W |
700W |
|
Manufacturing Process |
TSMC 4NP |
TSMC 4NP |
TSMC 4NP |
|
Interface |
Superchip |
SXM-Next? |
SXM-Next? |
|
Architecture |
Grace CPU + Blackwell GPU |
Blackwell GPU |
Blackwell GPU |
7. NVIDIA Blackwell B100 GPU và Blackwell B200 GPU
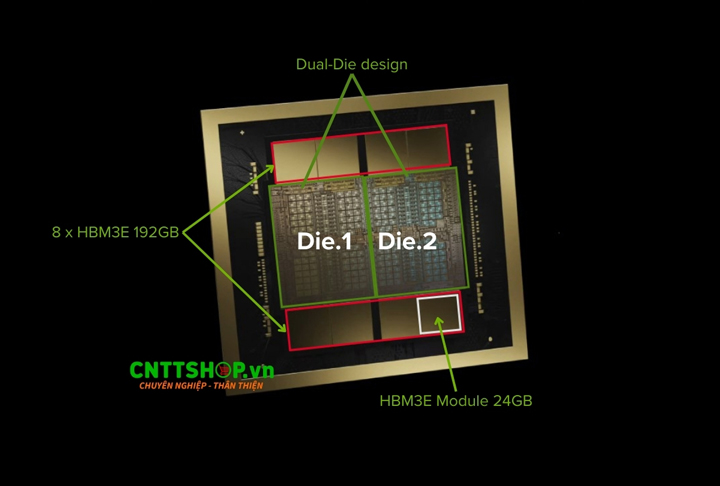
Nvidia Blackwell B100 GPU và Nvidia Blackwell B200 GPU là những GPU có thiết kế khuôn kép (dual-die design), trong đó mỗi khuôn chứa 04 module bộ nhớ HBM3e với dung lượng 24GB/Module và với băng thông bộ nhớ 1TB/s trên giao diện 1024-bit. Số lượng bóng bán dẫn trên GPU B100 và B200 là như nhau đều 104 tỷ / 1 Die hay 208 tỷ /2 Die tổng dung lượng RAM đều là 192GB và cùng băng thông bộ nhớ 8TB/sec. Nhưng B100 được thiết kế để đảm bảo mức tiêu thụ năng lượng là tối ưu nhất với TDP = 700W, trong khi đó B200 được thiết kế để đảm bảo cho môi trường tính toán hiệu năng cao hơn.
Blackwell B100 GPU được sử dụng để xây dựng các máy chủ AI HGX100 hiệu năng cao tiết kiệm năng lượng với 08 B100 GPU thông qua kết nối NVLink để hỗ trợ các nền tảng AI dựa trên x86. Blackwell B200 GPU được sử dụng để xây dựng các máy chủ AI HGX200 hiệu năng vượt trội với 08 B200 GPU với liên kết NVLink để hỗ trợ các nền tảng AI dựa trên x86

8. NVIDIA Blackwell GB200 GPU
Blackwell GB200 GPU là một siêu GPU nó được tạo nên từ sự kết hơp giữa 01 NVIDIA Grace CPU và 02 NVIDIA Blackwell, Blackwell GB200 GPU là thành phần cơ bản để tạo nên một hệ thống siêu tính toán NVIDIA GB200 NVL72

9. Kết luận:
Với việc giới thiệu kiến trúc ưu tú Blackwell cùng với các GPU mới B100, B200, GB200. Nvidia đã định nghĩa lại các mô hình AI Tạo Sinh và xây xựng các HPC (High-performance computing) với khả năng tính toán song song chưa từng có. Nó không những cho phép chúng ta có thể xây dựng các hệ thống tính toán thời gian thực với nhiều nghìn tỷ tham số, mà còn cho phép thực hiện mã hóa tất các các dữ liệu để đảm bảo sự an toàn, toàn vẹn của dữ liệu trong việc tính toán cũng như lưu chuyển giữa các node tính toán, nó cho phép doanh nghiệp tự xây dựng hệ thống phần cứng cho mô hình AI của mình với chi phí và mức tiêu thụ năng lượng phù hợp nhất.
Công ty Việt Thái Dương - CNTTShop hiện là nhà cung cấp các giải pháp hạ tầng CNTT, Điện toán Hiệu năng cao (HPC) cho AI với nhiều năm nghiệm tư vấn và kinh doanh. Chúng tôi luôn là đối tác tin cậy để các bạn lựa chọn cho việc tư vấn và tích hợp các giải pháp và sản phẩm chính hãng NVIDIA.
CNTTShop chuyên tư vấn các giải pháp chính hãng NVIDIA, HPC và AI
Hotline: 0906 051 599
Email: kd@cnttshop.vn





















Bình luận bài viết!